elasticsearch路由一个文档到一个分片的方法是什么
这篇文章主要讲解了“elasticsearch路由一个文档到一个分片的方法是什么”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“elasticsearch路由一个文档到一个分片的方法是什么”吧!
成都创新互联公司坚持“要么做到,要么别承诺”的工作理念,服务领域包括:成都网站设计、成都网站建设、外贸网站建设、企业官网、英文网站、手机端网站、网站推广等服务,满足客户于互联网时代的德惠网站设计、移动媒体设计的需求,帮助企业找到有效的互联网解决方案。努力成为您成熟可靠的网络建设合作伙伴!
当索引一个文档的时候,文档会被存储到一个主分片中。 Elasticsearch 如何知道一个文档应该存放到哪个分片中呢?当我们创建文档时,它如何决定这个文档应当被存储在分片 1 还是分片 2 中呢?
首先这肯定不会是随机的,否则将来要获取文档的时候我们就不知道从何处寻找了。实际上,这个过程是根据下面这个公式决定的:
shard = hash(routing) % number_of_primary_shards
routing 是一个可变值,默认是文档的 _id ,也可以设置成一个自定义的值。 routing 通过 hash 函数生成一个数字,然后这个数字再除以 number_of_primary_shards (主分片的数量)后得到 余数 。这个分布在 0 到 number_of_primary_shards-1 之间的余数,就是我们所寻求的文档所在分片的位置。
所有的文档 API( get 、 index 、 delete 、 bulk 、 update 以及 mget )都接受一个叫做 routing的路由参数 ,通过这个参数我们可以自定义文档到分片的映射。一个自定义的路由参数可以用来确保所有相关的文档——例如所有属于同一个用户的文档——都被存储到同一个分片中。
一个分片并不是没有代价的。记住:
一个分片的底层即为一个 Lucene 索引,会消耗一定文件句柄、内存、以及 CPU 运转。
每一个搜索请求都需要命中索引中的每一个分片,如果每一个分片都处于不同的节点还好, 但如果多个分片都需要在同一个节点上竞争使用相同的资源就有些糟糕了。
用于计算相关度的词项统计信息是基于分片的。如果有许多分片,每一个都只有很少的数据会导致很低的相关度。
在特定场景下这是一个容易回答的问题,尤其是你自己的场景:
基于你准备用于生产环境的硬件创建一个拥有单个节点的集群。
创建一个和你准备用于生产环境相同配置和分析器的索引,但让它只有一个主分片无副本分片。
索引实际的文档(或者尽可能接近实际)。
运行实际的查询和聚合(或者尽可能接近实际)。
基本来说,你需要复制真实环境的使用方式并将它们全部压缩到单个分片上直到它“挂掉。” 实际上 挂掉 的定义也取决于你:一些用户需要所有响应在 50 毫秒内返回;另一些则乐于等上 5 秒钟。
一旦你定义好了单个分片的容量,很容易就可以推算出整个索引的分片数。 用你需要索引的数据总数加上一部分预期的增长,除以单个分片的容量,结果就是你需要的主分片个数。
在索引写入时,副本分片做着与主分片相同的工作。新文档首先被索引进主分片然后再同步到其它所有的副本分片。增加副本数并不会增加索引容量。
无论如何,副本分片可以服务于读请求,如果你的索引也如常见的那样是偏向查询使用的,那你可以通过增加副本的数目来提升查询性能,但也要为此 _增加额外的硬件资源_。
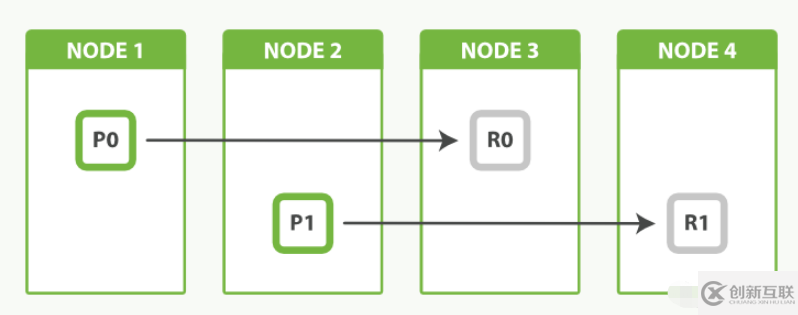
一个拥有两个主分片一份副本的索引可以在四个节点中横向扩展
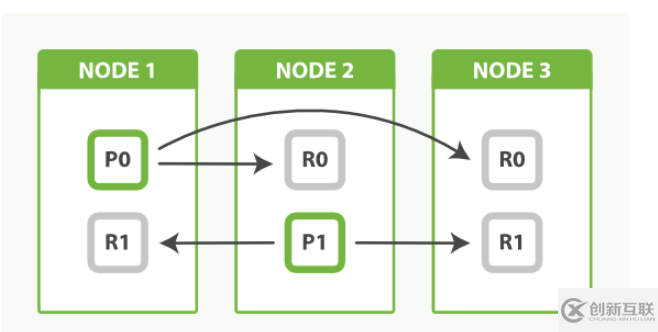
通过调整副本数来均衡节点负载
感谢各位的阅读,以上就是“elasticsearch路由一个文档到一个分片的方法是什么”的内容了,经过本文的学习后,相信大家对elasticsearch路由一个文档到一个分片的方法是什么这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是创新互联,小编将为大家推送更多相关知识点的文章,欢迎关注!
文章名称:elasticsearch路由一个文档到一个分片的方法是什么
网站URL:http://mswzjz.cn/article/gpsipe.html